introduction
It can be difficult to find a clear statement of what the Capital Asset Pricing Model (henceforth CAPM) is. I’m not trying to do much more than provide that. In particular, I did not find the wiki article to be useful, even after acquiring a couple of recent books on the subject.
I own six references:
- Sharpe, Wiliam F.; “Investments”, Prentice Hall, 1978; 0-13-504605-X.
- Reilly, Frank K.; “Investments”, CBS College Publishing (The Dryden Press), 1980; 0-03-056712-2.
- Gringold, Richard C and Kahn, Ronald N.; Active Portfolio Management, McGraw-Hil, 2000; 0-07-024882-6.
- Roman, Steven; Introduction to the Mathematics of Finance, Springer, 2004; 0-387-21364-3.
- Benninga, Simon; Financial Modeling, 3rd ed. MIT, 2008; 0-262-02628-7.
- Ruppert, David; Statistics and Data Analysis for Financial Engineering; Springer 2011; 978-1-4419-7786-1.
There is more than one version of the CAPM… Roman (p. 62) tells me that “The major factor that turns Markowitz portfolio theory into capital market theory is the inclusion of a riskfree asset in the model…. generally regarded as the contribution of William Sharpe, for which he won the Nobel Prize…. the theory is sometimes referred to as the Sharpe-Lintner-Mossin (SLM) capital asset pricing model.”
Then Benninga (p. 265) told me about “Black’s zero-beta CAPM… in which the role of the risk-free asset is played by a portfolio with a zero beta with respect to the particular envelope portfolio y.” (We’ll come back to this, briefly.)
Let me begin by writing what is usually called the (security) characteristic line. (It’s actually a poor name because the first thing we write is not a line, but a line plus disturbances.) We begin by asserting a model, that

R_i is a vector: the returns on an asset i (these may be daily, weekly, monthly, or perhaps even hourly)… think “IBM”.
R_f is a vector: the corresponding returns on the “risk-free investment”… think “30-year US Treasury bonds”.
R_m is a vector: the corresponding returns on the (risky) market as a whole… think “S&P 500”.
R_i – R_f is called the excess return of asset i; R_m – R_f is called the excess return of the market.
So what we’re looking at is nothing more than a linear model… to which we would want to fit data. I would not usually use r_i for the disturbances (errors) but it seems to be common in the literature. It is standard to assume that the expected value of the disturbances is zero: E(r_i) = 0. What we have is a form of the two-variable model

and we will do a least-squares fit to get a line
and then we would be able compute residuals 



Let me emphasize that X is a vector in this case, and both 
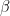
I am using a very common alternative notation to my usual: a hat to designate an estimate of an underlying parameter. I usually use it to distinguish Y and 


I think I will try to refer to
Third,, I’m going to use this post here as a springboard to show you a very interesting alternative method of calculation for the 2-variable model.
I propose to do five things:
-
review and rewrite the alternative calculation of
- use an illustrative example from Reilly:
- using the alternative calculation
- using the usual regression method
- review the jargon
- consider the variance of the excess return on an asset
- summarize it all briefly

The alternative algorithm
In the post about secrets of the correlation coefficient (same link as above) I showed you that it was algebraically convenient to write things in terms of centered data x and y (note: lower case) rather than the raw data X and Y (upper case), even though we were using a model and estimating parameters for X and Y. That is, for the model
and the least-squares line

it is convenient to define centered variables x and y as


where 

Then I showed that we could write

and I assert that the fitted line goes thru the mean-point 

– and we get

Then we can compute the R^2 as

or

or

or (taking a square root)

So?
Now we take a step further and rewrite the expressions x.y, x.x, and y.y . Because they are centered data, we could write



(I have written sample covariances and variances, but it doesn’t matter: the common factors of (n-1) will cancel, and if we had used n everywhere instead, they would all cancel, too. We just can’t use one for variance and the other for covariance!)
What we get is

and

or, my preference,

We retain
An aside:
Sharpe writes the equation

and yes, I meant to omit the hat from
Reilly’s Example
introduction
Let me work a small example from Reilly.
We are given 13 month-end prices for IBM from Dec 1978 thru Dec 1979 – but I’m not going to show them. We compute the following percentage monthly returns:

Check that these are ratios, using the first two given prices, 96.11 and 99.93:

Another aside:
Each of those returns was computed by taking 

We are also given month-end prices for the S&P 500 over the same period. Again, we compute percentage monthly returns:

We are apparently going to ignore the risk-free rate of return: we are setting R_f = 0.
the alternative calculations for the regression line
First we need the variance of Rm, and the covariance between Rm and Ri:

From those, we can compute

but convert that to
and then to


Next, we get the means of Ri and Rm…

and compute


Finally, we compute the variance of Ri,

and then compute the R^2 and R for the regression:

which translates to

(R is, in fact, the correlation coefficient between X and Y, i.e. between Rm and Ri.)
For the record, I would usually just recall


… then compute all 3 variances and covariances and the two means, and then write:

Reilly got .806, -1.94, and .78 . OK. Incidentally, the R^2 is unusually good for this kind of data: a much lower value, 0.3, is typical.
So, that’s one way to compute the coefficients of a least-squares line fitted thru our (X,Y) = (Rm, Ri) data. This is how the computation is usually presented in discussions of the CAPM.
But we know the usual way to fit a least-squares line, and we know that it gives us more information.
LinearModelFit
I need a 2-column matrix holding Rm and Ri:

We fit a line, naming the independent variable RI…

Let me get the parameter table, the RSquared, and let me construct a function for the fitted line:

We get 

I am impressed that both of his t-stats are significant, considering that we only had 12 data points. (I don’t actually believe these t-statistics – but they’re all we have. In particular, it is doubtful that the disturbances are normal.)
A negative parameter
Let me elaborate on that. We have
But
We also have
Let’s look at the data and the fit (this is why I defined a function for the fit):

jargon
Let’s return to our model:
That includes the equation of a line:

As I said at the beginning, that’s called the security characteristic line or just the characteristic line.
From Reilly I learned (p. 587) that “A risk-free asset is one for which there is no uncertainty regarding the expected rate of return; i.e. the standard deviation of returns is equal to zero ….”
He also told me (p. 588) that “The covariance between any risky asset or portfolio of risky assets and a risk-free asset is zero.” And that’s where Black’s zero-beta CAPM arises: if 

Returning to our model, we can collect terms:



Sharpe says of r_i: “By convention,
I guess I’m glad to see that he interprets the disturbances r_i as responses to information.
He also says, of
Oh, I have said that Sharpe worked a numerical illustration using an underlying probability distribution, so that he was computing the parameters
Finally, Ruppert points out that we often want to assume that for any two assets i and j, r_i is uncorrelated with r_j. Not a likely assumption, so we might want to combine assets into sectors, and argue that the disturbances to sectors are uncorrelated between different sectors.
But speaking of the variance/covariance of r_i leads to the question of the variance of the excess return on an asset.
Variance Decomposition
If we assume that the disturbances are not correlated with the market returns,
then from
in the form

we get

because 

So we have split the variance of asset i into market and nonmarket components. Now I hate to say it, but no one actually believes the assumptions leading to that, but they use the result anyway. Let me quote Ruppert (p. 423):
“The validity of the CAPM can only be guaranteed if all these assumptions are true, and certainly no one believes that any of them are exactly true.”
OK… the discredited assumptions are used to decide what assumptions they really want – and that decomposition of the variance is something they really want to assume.
I have to ask, however, about the estimates
No… we don’t need to. There is a perfectly valid decomposition for the sample variances. Let me write it using X and Y, because I don’t want to write r_i hat for the residuals, and I want to use my familiarity with X and Y. It is true that

(I confess I was glad to remember that that was true, and why. I know that
That decomposition is an immediate consequence of the sum-of-squares (SSQ) decomposition, which in turn is true because in a least-squares fit, the residuals
Total SSQ = Regression SSQ + Error SSQ.
(TSS = RSS + ESS)
Let me remind you of that. What we have is



= RSS + ESS

so

Divide that by n-1 (where n is the number of observations) and we get the decomposition for the sample variances (DVS):

where each 


I find two things interesting. One is that the DVS requires only that we do a least squares fit to a straight line. The least squares property guarantees that the residuals 
Now I need to quote Sharpe again (p. 107). “Three key measures summarize a security’s prospects…: 

![S(r_i) [= \sqrt{Var(r_i)}]\](https://s0.wp.com/latex.php?latex=S%28r_i%29+%5B%3D+%5Csqrt%7BVar%28r_i%29%7D%5D%5C+&bg=ffffff&fg=000000&s=0&c=20201002)
It seems to me that if the analyst’s estimates
Two… staying with X and Y… we contrast two equations, for the estimate

and the model

Lovely?
No.
An unbiased estimate of 
Huh?
It is not true that the estimated variance of Y is equal to 
And yet, in a sense, that’s a delightfully easy approximation. Run a regression, and take 
That’s what I’m now expecting to see when I look at examples.
Just don’t tell ever me that the sample variance of
Let me illustrate the differences. For Reilly’s example of IBM vs. the S&P 500, we have the estimated variance s^2 of the disturbances:

Now I need the residuals… their sum-of-squares ESS… and ESS/n-2:
d17

Yes, that’s the estimated variance – that is, an unbiased estimate of the nonmarket variance.
Now lets compute and save the sample variance of Y (i.e. R_i), with the marvelously descriptive name t1:

Next, compute the variance of X (i.e. R_m), and multiply by

Finally, compute and save the sample variance of

The sum of squares decomposition says that
t1 = t2 + t3

That the estimated non-market variance differs from the sample variance of the
t1 ≠ t2 + s^2

And it does not, of course.
And now I think I know why people are so vague about the distinction between the parameters
Oh, and if you, O Reader, are thinking, “Wait a minute! We know the mean of the residuals
I think I agree. But ESS/n is even further from ESS/(n-2). And the true decomposition
TSS = RSS + ESS
requires that we divide everything by the same number, whether it be n, n-1 (my preference), or n-2.
Summary
My summary of this entire thing? The simplest part of the CAPM is a standard linear model. Letting Y and X be the excess returns of an asset and of the market, we have
with disturbances e. We get a fitted line
which gives us
where
We saw that the estimates could be computed using variances of X and Y, and the covariance between them.
As usual in such models, the expected value of e is zero; and the sum of the
Moving on, we wish to decompose the variance of Y into the variance of X and of e, thinking of one as the market (systematic) component and the other as the unique (nonmarket, unsystematic) component:

In practice, I expect that they decompose using the sample variances of X and, incorrectly but easy, of

I’ll be looking at the variance decompositions I see in practice.
Bear in mind that this post is based on a few schoolboy references… I’ve not been in the back room of a quant shop seeing what they really do! (Gringold and Kahn may give me more of that experience, but their mathematics seems a little too vague. That’s why I bought Ruppert, and Benninga, and there’s another book due in a couple of days.)

May 14, 2019 at 7:33 am
must specified that these stated from prof dr orasanu and prof drd horia orasanu in connexion with whittaker formula with contributions of our