(abuse of) terminology
Sometimes I get tired of writing “xbar, ybar, zbar tables” — and I just write “xyz bar tables” or even “XYZ tables”. Similarly for rbar, gbar, bbar tables — rgb bar. I’m not talking about anything new, just abbreviating the names.
Introduction
This is the third post about the example on p. 160 of W&S. Once again, I am going to decompose the reflected spectrum into its fundamental and its residual.
This time, however, I’m going to use the rbar, gbar, bbar tables (RGB) instead of the xbar, ybar, zbar (XYZ) tables. They did not do this.
I’ll tell you now there is one little twist in these calculations. We will need the ybar table, because we still need to use it to scale our results.
In addition to showing, as I did previously, the dual basis spectra and the orthonormal basis spectra for the non-nullspace, I will display the orthonormal basis for the nullspace.
Read the rest of this entry »
 for the SVD of X.)
for the SVD of X.)

 is very well behaved. Its two columns are orthogonal to each other:
is very well behaved. Its two columns are orthogonal to each other: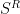 are the components wrt the reciprocal basis, we ought to find the components wrt the
are the components wrt the reciprocal basis, we ought to find the components wrt the 



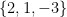
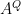 is the new data wrt the orthogonal eigenvector matrix; and i hope i’ve said that the R-mode scores
is the new data wrt the orthogonal eigenvector matrix; and i hope i’ve said that the R-mode scores  are not the new data wrt the weighted eigenvector matrix
are not the new data wrt the weighted eigenvector matrix 

 , from a vector space V to the same vector space V. in fact, i have more than a vector space: V is an inner product space; i have a “dot product”.
, from a vector space V to the same vector space V. in fact, i have more than a vector space: V is an inner product space; i have a “dot product”.  .
.
 ,
,