Rather than edit the following SVD posts – unless I have to – let me put some prefatory material here. I am also going to answer a couple of email questions in comments, partly just to check out their mechanics.
The following posts in the math SVD category should be read in the order displayed, not starting from the back.
That may have been a bad idea on my part, but let’s see how it works out. The difficulty is that most of what I do out here will be available in the usual blog-order, latest first. Eventually it may be awkward if one category is in reverse order wrt everything else.
I would like to add two pieces of vocabulary. For the SVD 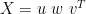
I have also discovered that the latex interpreter works in comments. Cool! My understanding is that it does not work in forums; they would be the appropriate place to post code – and have it display as code! After all, that’s where I found the key starting points for latex.

 is not only a diagonal matrix but it has only positive elements. Finally, we order the elements of w from largest to smallest(don’t sweat it if some are equal).
is not only a diagonal matrix but it has only positive elements. Finally, we order the elements of w from largest to smallest(don’t sweat it if some are equal). as the conjugate transpose of v in everything i do.)
as the conjugate transpose of v in everything i do.) [diagonalization]
[diagonalization]
 [eigenvector decomposition]
[eigenvector decomposition] [change of bases]
[change of bases] .
. by
by  because P is an arbitrary invertible matrix: we may have made any legal change-of-basis, not the special case of a rotation.
because P is an arbitrary invertible matrix: we may have made any legal change-of-basis, not the special case of a rotation. :
: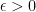 .
. ;
;





 .
. .
. . you should expect that it uses u instead of v.
. you should expect that it uses u instead of v.


 .
. .
. . That is,
. That is,  (they’re not even the same size), but both are diagonal, and both have the same nonzero entries. In fact, and we want to know this,
(they’re not even the same size), but both are diagonal, and both have the same nonzero entries. In fact, and we want to know this,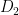 are the squares of the nonzero entries in w.
are the squares of the nonzero entries in w. , and
, and diagonal, all elements positive.
diagonal, all elements positive. or
or 

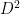
 by analogy with the impossible (because w is not invertible)
by analogy with the impossible (because w is not invertible) 
