So far, there are only two that I know of. One is here in “attitude & transition matrices”; the other is here in “the SVD generalizes eigenstructure”.
I was reading yet another book on PCA / FA last night, and I came across a definition saying that two matrices A and B were similar if . Of course, I objected that P needed to be orthogonal, and we couldn’t guarantee that in general. This morning, out with one of the cats – and, therefore, thinking instead of computing or writing! – I observed that the author had made that mistake because the matrices
. Of course, I objected that P needed to be orthogonal, and we couldn’t guarantee that in general. This morning, out with one of the cats – and, therefore, thinking instead of computing or writing! – I observed that the author had made that mistake because the matrices 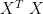 and
and 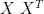 are symmetric, and for symmetric matrices it is certainly true that P may be chosen orthogonal. He had been careless because within the realm of PCA / FA, we are only finding eigendecompositions of symmetric matrices. Within the realm of PCA / FA, we may take P to be orthogonal, because we’re looking at and/or when we’re not using the SVD.
are symmetric, and for symmetric matrices it is certainly true that P may be chosen orthogonal. He had been careless because within the realm of PCA / FA, we are only finding eigendecompositions of symmetric matrices. Within the realm of PCA / FA, we may take P to be orthogonal, because we’re looking at and/or when we’re not using the SVD.
It was a while after that I began to wonder if I had made the very same mistake.
I had. Damn!
I have corrected it. It was in among the SVD posts, specifically “the SVD generalizes eigenstructure”. if someone else had written my post, I think I would have caught that. Unfortunately, when I read my own stuff, I sometimes read what I meant to write, instead of what I did write. (That’s how I learned to let another grad student take a test before I handed it out to my students. He’d have to read what I wrote; take it myself, and I don’t even stop to read the questions!)
As I said, if A is symmetric, we may choose P orthogonal. More generally, if A is hermitian, we may choose P unitary. In ultimate generality, we may choose P unitary if and only if A is normal.
I have even shown you that we cannot always have P unitary. The counterexample in the schur’s lemma post was specifically a non-normal matrix which could be diagonalized, but whose eigenvectors were not orthogonal, i.e. whose eigenvector matrix was not, and could not be made, unitary.
FWIW, for any 3D rotation matrix – which is orthogonal, hence normal – we may choose P unitary but not orthogonal: even though the rotation matrix is real, its eigenvector matrix is complex and can only be made unitary.



 ,
, on a computer may be extremely hazardous.
on a computer may be extremely hazardous.






