Quite some time ago, a friend asked me what would happen if we tried to construct a torus by gluing all 4 sides of a sheet of paper together, instead of first one pair then the other. Didn’t the math have to specify first one pair then the other?
One reason I’ve been hesitating over this post is that it doesn’t seem to be “real” mathematics – though any number of people might howl that PCA / FA isn’t “real” mathematics either. This is just a small drawing that I cobbled together to show that the homeomorphism between a circle and a line segment with endpoints identified… well, it doesn’t have to correspond to a physical process. (Why don’t I refer to “the glued line”?)
“… algebra provides rigor while geometry provides intuition.”
from the preface to “A Singular Introduction to Commutative Algebra” by Greuel & Pfister
It helped me to go back and read my original comment when I acklowledged Jim’s question to this post. I see that I did not understand that what matters to the formalism, the algebra, is before and after; what matters to the geometry is between or during. We reconcile them by permitting some things in the geometric visualization that we would not permit in the formal algebra, if the algebra even formalized the process: points passing thru points; or even some tearing, if when we reglue it we restore it rather than take the opportunity to change it.
That’s what bloch says, on p.57, discussing the physical process of getting from the knotted torus

to the regular torus.
Read the rest of this entry »



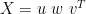
 (in 2 cases, that’s the correlation matrix or the covariance matrix)
(in 2 cases, that’s the correlation matrix or the covariance matrix)



 .
.
 , X standardized, and A a
, X standardized, and A a  -weighted eigenvector matrix, with eigenvalues from the correlation matrix.
-weighted eigenvector matrix, with eigenvalues from the correlation matrix. in the case that A was invertible (
in the case that A was invertible ( that shows up when we relate the
that shows up when we relate the  of a correlation matrix to the principal values w of the standardized data
of a correlation matrix to the principal values w of the standardized data
 where
where 
 -weighted eigenvector matrix,
-weighted eigenvector matrix, 

 is the diagonal matrix of (nonzero)
is the diagonal matrix of (nonzero)  , X is the standardized data.
, X is the standardized data. is the associated eigenvalues, possibly as a list, possibly as a square diagonal matrix.
is the associated eigenvalues, possibly as a list, possibly as a square diagonal matrix.  , possibly as a list, possibly as a square matrix, and possibly as a matrix with rows of zeroes appended to make it the same shape as w (below).
, possibly as a list, possibly as a square matrix, and possibly as a matrix with rows of zeroes appended to make it the same shape as w (below). , with u and v orthogonal, w is generally rectangular, as it must be the same shape as X.
, with u and v orthogonal, w is generally rectangular, as it must be the same shape as X.
