The Posts
The purpose of this post is to provide guidance to a reader who has just discovered that I have a large pile of posts about principal components / factor analysis. This pile of posts might seem a very jungle, without any map.
Here, have a map.
As I finalize this post, it will be number 52 in PCA / FA. Here’s a list of the 52 posts, including the dates spanned by any group, and the number of posts in that group. (When the picture was taken, I didn’t know when this would be published. In fact, post 51 was scheduled but not yet published. Even more, post 51 did not even exist when the first picture was created.)

transition/attitude matrices is a post that is sometimes relevant when we discuss “new data” in PCA, but it is not in the PCA / FA category.
“tricky prepro” is short for “tricky preprocessing”, and discusses the combination of constant row sums and covariance or correlation matrix.
Read the rest of this entry »
 ,
,  ,
,  is the diaginal matrix of eigenvalues. We define the
is the diaginal matrix of eigenvalues. We define the  -weighted matrix
-weighted matrix .
. .
. .
.


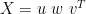
 (in 2 cases, that’s the correlation matrix or the covariance matrix)
(in 2 cases, that’s the correlation matrix or the covariance matrix)



 .
.
 , X standardized, and A a
, X standardized, and A a  -weighted eigenvector matrix, with eigenvalues from the correlation matrix.
-weighted eigenvector matrix, with eigenvalues from the correlation matrix. in the case that A was invertible (
in the case that A was invertible (