introduction
A long time ago, in a post about PCA (principal component analysis), I said that I did not know what Andrews curves were. (The suggestion was made that Andrews curves might help us decide how many principal components to keep. I did not understand how they were to be computed.)
Now I know. Let me show you. I will compute Andrews curves for what is called “the iris data”… for both the full data set (150 observations) and a reduced data set (30 observations). I will also show you a possible variant.
In addition, we will know that there are in fact three kinds of irises in the data – so we can assess how well the Andrews curves did. In practive, of course, we will be trying to figure out how many kinds of observations we have.
The data is here. The paper which explained Andrews curves to me is here. Andrews original paper is: Andrews D. Plots of high-dimensional data Biometrics 1972 28:125-136… but I haven’t found it freely available anywhere online.
In addition, there is a short and sweet webpage by one of the authors of the paper I read.
Read the rest of this entry »
 .
. we conclude that v is an eigenvector matrix for
we conclude that v is an eigenvector matrix for 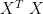 , and u is an eigenvector matrix for
, and u is an eigenvector matrix for  . and, just as important, the nonzero values of w are the nonzero
. and, just as important, the nonzero values of w are the nonzero  .)
.)


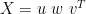 the columns of u and v are called the left singular vectors of X
the columns of u and v are called the left singular vectors of X