(June 10: i have made 4 edits, all cosmetic. you may search on “edit:”)
Malinowski (edit: “Factor Analysis in Chemistry”, 3rd ed.) does a lot of things differently from what we’ve seen. Fortunately, his model is simple enough, although his notation is… different. His model is
X = R C,
and he calls R and C the row and column matrices respectively. He wants X to have more rows than columns, so he transposes if necessary; then he chooses C to have more columns than rows, and R will have more rows than columns. For starters, then, his X matrix looks like the usual design matrix for regression. (Incidentally, he didn’t call it X.)
He chooses  , from the cut-down SVD. That is, I write the SVD of X as
, from the cut-down SVD. That is, I write the SVD of X as
 ,
,
where u and v are orthogonal and w is the same shape as X. But we know from the derivation and our experience with Davis that we may also write
 ,
,
where  is square, diagonal, and invertible (it is a cut-down w), and
is square, diagonal, and invertible (it is a cut-down w), and  and
and  are the submatrices of u and v which are conformable with . (We’ll see all this shortly.) We have dropped the parts of u, w, and v which are not required for reproducing X. (I remind you that what we’ve lost is the orthogonality of the matrices u and v.)
are the submatrices of u and v which are conformable with . (We’ll see all this shortly.) We have dropped the parts of u, w, and v which are not required for reproducing X. (I remind you that what we’ve lost is the orthogonality of the matrices u and v.)
Read the rest of this entry »
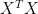

 vectors. (His x and
vectors. (His x and 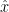 are usually written y and
are usually written y and  for a least-squares fit). He finds a possible x and tests it to see if xhat is close. He recommended computing an intermediate t vector which was the
for a least-squares fit). He finds a possible x and tests it to see if xhat is close. He recommended computing an intermediate t vector which was the  for his least-squares fit to x.
for his least-squares fit to x.

 will be successful.” He gives us a formula for computing t; by a successful regeneration, he means that
will be successful.” He gives us a formula for computing t; by a successful regeneration, he means that  is close to x.
is close to x.