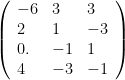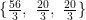When I moved beyond the first couple of books, I was bewildered by the huge number of alternatives for PCA / FA. I think my final count was that there were 288 different ways of doing it. It was so bad that I put together a form so that whenever I read a new example I could check off boxes for the choices made. As I’ve gotten more experience, I no longer need that checklist.
A lot of those choices pertained to the starting point. If the analysis began with an eigendecomposition, well, it could have been applied to the correlation matrix, or to the covariance matrix – oh, and one text used N instead of N-1 to compute sample variances.
Or an eigendecomposition could have been applied to 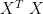
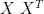
Or we could have done an SVD of X, where X itself could have been raw data, centered data, doubly-centered data, standardized data, or small standard deviates, with observations in rows or columns. Yikes!
(not to mention that the data could very likely have been manipulated even before these possible transformations.)
Then I decided that all those choices were pre-processing, not really part of PCA / FA. Actually, I decided that I must have been careless, and missed the point when everyone made it, that one had to decide what pre-processing to do before starting PCA / FA. I was kicking myself a bit.
Read the rest of this entry »
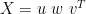
 .
.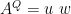 .
. .
. .
.

 and the eigenvector matrix A. Here’s A:
and the eigenvector matrix A. Here’s A: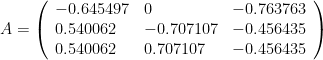
 and get an identity matrix, then A is orthogonal. (it is.)
and get an identity matrix, then A is orthogonal. (it is.) for the SVD of X.)
for the SVD of X.)

 is very well behaved. Its two columns are orthogonal to each other:
is very well behaved. Its two columns are orthogonal to each other: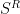 are the components wrt the reciprocal basis, we ought to find the components wrt the
are the components wrt the reciprocal basis, we ought to find the components wrt the 


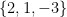
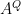 is the new data wrt the orthogonal eigenvector matrix; and i hope i’ve said that the R-mode scores
is the new data wrt the orthogonal eigenvector matrix; and i hope i’ve said that the R-mode scores  are not the new data wrt the weighted eigenvector matrix
are not the new data wrt the weighted eigenvector matrix