The following books have been added to the bibliography page. They were mentioned in today’s “Happenings”. One is control theory, two are upper division physics books, and one is a popular book about physics.
Carstens, James R.; Automatic Control Systems and Components.
Prentice Hall, 1990. ISBN 0 13 054297 0
[classical controls; 25 feb 2008]
this book caught my eye when i saw that he had transfer functions for specific devices used in control systems; it won my heart when he distinquished between the parameters in his math models and the parameters to be found in catalogs!
This is an introductory and hands-on book.
Zwiebach, Barton; A First Course in String Theory.
Cambridge University Press, 2004. ISBN 0 521 83143 1.
[string theory; 25 feb 2008]
This is the text for an upper-division couse at M.I.T.
Lederman, Leon, with Teresi, Dick; The God Particle.
Bantam Doubleday Dell, 1993. ISBN 0 385 31211 3.
[popular physics, particle physics; 25 feb 2008]
This is a popular book, and I had forgotten just how much fun it was to read. Even if you’ve seen The Standard Model of particles, you may enjoy this book; and if you don’t know the standard model, this is a fine place to start. (The title refers to the Higgs boson; it was that or the god-damned particle, he said.)
Griffiths, David; Introduction to Elementary Particles.
Wiley-VCH, 1987. ISBN 0 471 60386 3.
[elementary particle physics; 25 feb 2008]
An upper-division text. I really like his style, as well as his apparent precision. For an example of style: “In general, when you hear a physicist invoke the uncertainty principle, keep a hand on your wallet.”

 , we see that the dot products among all the vectors are:
, we see that the dot products among all the vectors are:





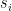 .
.

 , which are 1, become variances
, which are 1, become variances  , and each off-diagonal correlation
, and each off-diagonal correlation  becomes a covariance. maybe it would have been more recognizable if i’d written
becomes a covariance. maybe it would have been more recognizable if i’d written






