Consider the diagonalization of a matrix:
 ,
,
or
 .
.
A friend asked me why I couldn’t always choose P to be an orthogonal (more generally, a unitary) matrix. Actually, it was more like: remind me why I can’t do that. I fumbled for the answer. Sad dog.
We recall that an orthogonal matrix Q is real, square and satisfies
 ,
,
where  is the transpose of Q. That is to say, the inverse of Q is its transpose:
is the transpose of Q. That is to say, the inverse of Q is its transpose:  . If our eigenvector matrix P is orthogonal, we may replace
. If our eigenvector matrix P is orthogonal, we may replace
.
by
 .
.
A unitary matrix is complex (possibly real), square and satisfies
 ,
,
where is the conjugate transpose of Q. That is to say, the inverse is the conjugate transpose:
is the conjugate transpose of Q. That is to say, the inverse is the conjugate transpose:  .
.
Finally, we recall that a matrix is normal if it commutes with its complex conjugate:
 .
.
Now we have to go all the way back to the schur’s lemma post here and recall that
- Any matrix A can be brought to upper triangular form by some unitary matrix.
- A matrix A can be diagonalized by some unitary matrix if and only if A is normal.
That is to say, our guaranteed upper triangular matrix is in fact diagonal if and only if A is normal.
Return to our diagonalization: we have
,
By (2), if A is not normal, then P cannot be unitary; if, in addition, P is real, then P cannot be orthogonal.
I suppose I should remind us all that the matrices 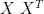 and
and 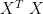 (cf. covariance and correlation matrices, R-mode and Q-mode) are normal, so that if we diagonalize them, our eigenvector matrices are orthogonal.
(cf. covariance and correlation matrices, R-mode and Q-mode) are normal, so that if we diagonalize them, our eigenvector matrices are orthogonal.
As for the SVD,  , we are using two matrices u and v, not one matrix P, and u and v are guaranteed unitary.
, we are using two matrices u and v, not one matrix P, and u and v are guaranteed unitary.
As for my fumbling the answer…. A old friend said that you understand something when it’s intuitively obvious. Well, it just is not intuitively obvious to me that normality of the one gives me orthogonality of the other. I should probably take another look at the proof…. In the meantime, I’ll try to just remember the answer.

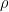 and
and  :
:



