Edit 7/12/12. Write ![Z[(1+\sqrt{-19})/2]\](https://s0.wp.com/latex.php?latex=Z%5B%281%2B%5Csqrt%7B-19%7D%29%2F2%5D%5C+&bg=ffffff&fg=000000&s=0&c=20201002)
Edit 7/17/12. Write 

The material I’m about to introduce comes from a 1st undergraduate course typically called abstract or modern algebra.
What I really want to talk about are number systems of the form

where D is an integer, negative or positive (and in some cases numbers of the form 
The fundamental theorem of arithmetic is the one that says that any integer can be written essentially uniquely as a product of primes.
Consider, however, the products

That is a big deal – because in the system of numbers of the form
![Z[\sqrt{-5}] = a + b \sqrt{-5}\](https://s0.wp.com/latex.php?latex=Z%5B%5Csqrt%7B-5%7D%5D+%3D+a+%2B+b+%5Csqrt%7B-5%7D%5C+&bg=ffffff&fg=000000&s=0&c=20201002)
all 4 of those numbers are irreducible: they themselves cannot be factored.
By contrast, we have (in the integers)

We can write 12 in more than one way… but only one of those three ways is a product of primes, i.e. a product of numbers which themselves cannot be factored into other integers.
But the number 21 cannot be written uniquely as a product of numbers which themselves cannot be factored in ![Z[\sqrt{-5}]\](https://s0.wp.com/latex.php?latex=Z%5B%5Csqrt%7B-5%7D%5D%5C+&bg=ffffff&fg=000000&s=0&c=20201002)
We say the system of numbers
Looking at numbers of this form is my goal… but I figure I owe you an introduction to rings before I jump right into quadratic integer rings.
In fact, I’m in the mood to write up some pretty fundamental stuff.
Let me start with the definition of an ordered pair. We’ve known what they are since the first time we did cartesian geometry, drawing our nice x- and y-axes and assigning (x,y) coordinates to points in the plane. The challenge, however, is to come up with a definition – using sets – that captures what we know, and gives us a rigorous definition which we can use.
This is a clever trick. In my opinion, at least, it is far from obvious. The ordered pair (a, b) is defined as the set of sets { {a}, {a,b} }. This permits us to distinguish a from b – one is in a singleton set, the other occurs only in a doublet; although a also occurs in the doublet, that isn’t the only place it occurs. We may call a the first component, and b the second component of the ordered pair. From this definition we may derive all the familiar properties of ordered pairs.
Then we can define the cartesian product AxB of sets A and B as the set of ordered pairs, where the first component comes from A and the second from B:

Now we can define a function. Really define one… not as “a machine that takes an input and delivers an output”, or some such typical definition from an introductory calculus course.
A function f from A to B is a subset of AxB such that
if 

if (a,b) and (a,c) are in f then b = c.
We usually write the first condition as f(a) = b. We may write the second condition as:
if f(a) = b and f(a) = c then b = c.
The first condition says that the function is defined on all of A. The second condition says that the function is single-valued. To put those another way, the first condition says that f(a) is defined, and the second condition says that f(a) is unique.
It is crucial that the definition of a function includes the sets A and B. It is not a rule tacked on to the definition – the sets A and B specify AxB, of which f is a subset. This means, for example, that f restricted to a subset C of A… is a different function from f, because the restricted function is a subset of CxB.
The set A is called the domain of the function f; the set B is called the codomain of the function. We let the expression f(A) denote the image (or range) of the function… i.e. the set of all b such that f(a) = b, for some a in A:

Note that we have not required that the image equal the codomain: in general, f(A) ≠ B. When we do have f(A) = B, the function f is said to be onto (or surjective).
We have also not required that if (a,b) and (c,b) are in f, then a = c. When that condition does hold, the function f is said to be 1-1 (one-to-one, or injective).
- The line y(x) = x is 1-1; the parabola y(x) = x^2 is not, because y(x) = y(-x).
A binary operation * on a set G is a function *: G*G -> G. That the codomain is G says that a binary operation is closed: the result is in G.
If for all a, b, c in G we have
a * (b * c) = (a * b ) * c,
then the binary operation is associative. If for all a and b in G we have
a * b = b * a,
then the binary operation is said to be commutative.
- The vector cross product is a binary operation which is neither commutative nor associative;
- matrix multiplication is an associative binary operation which is not commutative.
- The dot product of two vectors is not a binary operation at all, because it maps a pair of vectors to a scalar instead of to a vector.)
One way to define a group is to say that a group is a nonempty set G with a binary operation * on G such that:
- * is associative
- there is an identity element e in G such that e g = g e = g for every element g in G
-
for every element g in G there is an inverse
in G such that
.
(If you want to look at groups right now, you could start with this post.)
Although I have referred to the group G, sometimes we indicate the binary operation explictly, and refer to the group <G, *>.
(We did see, in the introduction to groups, that we could have assumed just the existence of a left identity, and the existence of left inverses, and ended up with an identity and (two-sided) inverses.)
We do not require that * be commutative, but if it is, we say that the group is abelian.
Anyway, a group is a set with one binary operation. But all of our number systems have two operations….
A ring R is a set with two binary operations + and * (called addition and multiplication) such that:
- <R, +> is an abelian group
- multiplication is associative
- multiplication is distributive over addition.
A ring is commutative if * is commutative. A ring has a unity (or has 1, or has an identity) if there exists an element 1 such that
1 * a = a *1 for all a in R.
That is, a ring has unity if there is a multiplicative identity.
If a ring has 1, then the distributive laws imply that addition is commutative. That’s one motivation for requiring <R,+> to be an abelian group – if the ring is to have an identity, then its additive group must be abelian.
In principle we could take a set containing one element, 0, and define 0+0 = 0 and 0*0 = 0, and we have a ring. In fact, we have a ring with identity: since 0*a = a for all a in the ring (namely a = 0 itself), 0 is an additive identity as well as a multiplicative identity. This is called the zero ring or the nullring.
We get a fundamental proposition:
if R is a ring, then
- 0a = a0 = 0
- (-a)b = a(-b) = -(ab)
- (-a)(-b) = ab
- if R has 1, then 1 is unique and -a = (-1)a.
- if a ring not the nullring has 1, then 1 ≠ 0.
So: (-1)(-1) = 1 is a ring property. The next time someone asks why it’s true, you can show them. Oh, should I show you the proof?
Prove (2) by showing that (-a)b and a(-b) are both additive inverses for ab, hence equal by definition to -(ab). Then prove (3) by using (2) with b replaced by (-b).
It’s rather convenient that -a = (-1)a in a ring with identity. (That’s an understatement!) Let me be clear: -a is the additive inverse of a, while (-1)a is the product of the additive inverse of 1 and a.
It’s time to list some examples of rings. First, here are some extremely familar rings (except perhaps the quaternions, I hope):
- the integers Z
- the rationals Q
- the reals R
- the complex numbers C
- the quaternions H
- the integers mod n (Zn)
Then we can build a whole family of rings of matrices. We could start with
- 2×2 matrices with integer entries (i.e. entries from the ring Z)
We could
- generalize from 2×2 to nxn
- generalize from Z to Q, R, C, H, or Zm
- generalize to any ring at all
Let me be clear: the set, say, of 3×3 matrices with entries only 0 or 1, is the ring of matrices with entries from Z2, often written 
We could also take
- upper (or lower) triangular matrices (including the diagonal… or not)
and I have by no means listed all possible rings!
Just as the zero ring is an extreme case, we could create some more extreme cases:
- given any abelian group G, make it a ring by adjoining 0, and defining multiplication so that every product is 0: xy = yx = 0 for all x,y in G.
Then, a couple of examples of even less familiar rings: for any fixed integer n
-
numbers of the form
, with a,b rational.
- ditto with a and b integer.
- (for n > 0) the nth roots of 1.
Then a set of examples that you may never have seen:
- the even integers, i.e. all multiples of 2
and more generally
- the integers nZ, i.e. all multiples of n.
Finally, there is a crucial ring: start with any ring R, and consider all polynomials in x with coefficients from R. With addition and multiplication defined as we are used to, the result is a ring, denoted R[x]. That is, if R is a ring, then R[x] is a ring.
(Additionally, if R is commutative then R[x] is commutative… if R has identity, then R[x] has identity… and (oh, joy) if R is a UFD – a unique factorization domain, in which the fundamental theorem of arithmetic holds – then R[x] is also a UFD.)
We can generalize to polynomials in more than one variable; and more general than polynomials, we have rings of functions with pointwise multiplication and addition.
Now, some of these examples have a few more properties than generic rings. The rationals, reals, and complex numbers, for example, are called fields: every nonzero number has a multiplicative inverse. The quaternions have that property, too – but they are not commutative, so they are called a division ring rather than a field.
We define a division ring (or skew field) as a ring with unity in which every nonzero element has an inverse… then a field is a commutative division ring.
(I strongly prefer the term division ring to skew field. In a rational naming system, if a field is commutative then a non-commutative field – or a skew field – is a contradiction in terms. On the other hand, I strongly suspect that not all that long ago, a division ring was required to be non-commutative, so that a field was not considered a special case (commutative) of a division ring.)
The integers mod n fall into two classes. For n a prime, we have a field. For n not a prime, we do not. In fact, for n not a prime, we have what are called zero divisors.
Consider Z4 = {0,1,2,3} with addition and multiplication mod 4. What’s 2×2 mod 4? It’s still 4, but that’s 0 mod 4… so we have 2×2 = 0 mod 4. By contrast, we rely on the fact that ab = 0 implies a = 0 or b = 0 in our usual number systems (integers, rationals, reals, complexes).
For Z6 ={0, 1,2,3,4,5}, we have
2*3 = 6 mod 6 = 0 mod 6
so that both 2 and 3 are so-called zero divisors in Z6: nonzero elements a and b of a ring are each called a zero-divisor if ab = 0. We distiguish the two variants of Zn by calling a commutative ring with unity and without zero divisors an integral domain. So Z2 and Z3 are integral domains, while Z4 and Z6 are not; more generally, Zp is an integral domain if and only if p is a prime.
You may know more: that Z2 and Z3 (Zp in general) are fields, not just integral domains. This is an example of two general facts – oh, if the underlying set R has a finite number of elements, we say the ring <R, +, *> is finite.
The two facts are:
- any field is an integral domain (if a number x has a multiplicative inverse then x cannot be a zero divisor… and every nonzero x in a field has an inverse)
-
any finite integral domain is a field.
I really should mention a much harder theorem, too. This is called Wedderburn’s Theorem:
- any finite division ring is a field.
Those theorems mean that some examples of things must be infinite. There’s no point in looking for a finite non-commutative division ring. There’s no point in looking for a finite integral domain that is not a field.
Let me draw a Venn diagram to show the inclusions.

For our universe we take the set of all rings. Some are commutative, some have unity, some are/have both. Some commutative rings with unity have zero divisors, some do not; those that do not are called integral domains. Some integral domains are fields.
Let me emphasize a handful of these examples.
The most specialized is a field: we might take the rationals as our canonical example.
If we lose commutativity, we have a division ring: e.g. the quaternions.
If, instead, we lose that every nonzero element has a multiplicative inverse, we get an integral domain, such as the integers Z. Also the integers mod a prime, Zp – but they are in fact a field.
A merely commutative ring with unity? Zn, with n composite.
A commutative ring without unity? The even integers.
A noncommutative ring with unity? 2×2 matrices with integer entries.
A noncommutative ring without unity? 2×2 matrices with even integer entries. (That excludes the identity matrix.)
Now let me elaborate on the two innermost circles:

In complete contrast to the beginning of this post, I’m going to be vague for a while.
There are integral domains called Euclidean domains. A Euclidean domain is an integral domain in which we can do long division (“the Euclidean algorthim”). One of the keys to long division was that when we divided n by d, we stopped when we had a remainder r less than d:
n/d = q + r/d, so that r/d was a proper fraction (or zero)
which we may write
n = q d + r, so that r < d.
In order to call something a Euclidean domain, then, we have to have a measure of size, so that we can speak of one ring element as being less than another.
Did you ever learn to divide polynomials in high school or early college? There we use the degree of a polynomial as our measure of size.
I would say that the crucial benefit of the Euclidean algorithm is that it lets us find greatest common divisors.)
Every field is a Euclidean domain, because r = 0 in every case.
Then there are integral domains called principal ideal domains.
Recall that a normal subgroup N of a group G is one which is the kernel of some group homomorphism f: we have f(N) = the identity subgroup. Well, an ideal is the exact ring analog of a normal subgroup. A subring is an ideal J if it is the kernel of some ring homomorphism g; that is, g(J) = {0} (yes, the additive identity).
An integral domain is called a principal ideal dimain (PID) if every ideal is generated by one element.
The integers are a PID because its ideals are precisely the multiples by one fixed integer. Each of Z (=1Z), 2Z, 3Z, 4Z, … nZ is an ideal, and each is generated by n. (2Z is just the even integers; 3Z is all the multiples of 3, etc.)
The reals (and any field) are a PID because the only ideals of a field F are {0} and F itself. But more: any Euclidean domain is a PID.
Then, as I have said, there are integral domains called unique factorization domains (UFD). It turns out that every PID is a UFD.
We have the following Venn diagram:

To put that picture in words: every field is a Euclidean domain, every Euclidean domain is a PID, every PID is a UFD, and every UFD is an integral domain. I want to study some specific UFDs… but what I say will be true for PIDs and Euclidean domains and, perhaps trivially, for fields.
(It’s not unusual for an introductory book to focus on PIDs and Euclidean domains, relegating UFDs to starred chapters that can be skipped. I just want to be clear that they are special cases of UFDs.)
Even better, those inclusions are proper (thank you, Dummit & Foote):
- Z is a euclidean domain but not a field…
-
- Z[x] is a UFD but not a PID…
-
(By 
![Z[\frac{\sqrt{19}}{2}]\](https://s0.wp.com/latex.php?latex=Z%5B%5Cfrac%7B%5Csqrt%7B19%7D%7D%7B2%7D%5D%5C+&bg=ffffff&fg=000000&s=0&c=20201002)
Let me close with a long aside.
The early development of rings was twofold: they were number systems, and they were collections of polynomials. I think I can say that ideals were created in order to deal with the failure of unique factorization… but the place to learn about ideals is the solution sets of polynomials (“varieties”).
I hope you know that a polynomial of degree n has precisely n complex roots, some of which may be repeated.
But the equation of a circle
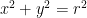
is a polynomial of degree 2 in two variables – and it has an infinite number of roots, namely the entire circle. Life gets interesting when we go to polynomials in more than one variable. An excellent undergraduate text is Cox, Little and O’Shea, “Ideals, Varieties, and Algorthms”.
The next post in this sequence will look more closely at integral domains. I don’t yet know if it will get to the details of non-unique factorization.

April 1, 2019 at 10:17 am
this algebra is very important that concern rings of radical and irrational numbers observed prof dr mircea orasanu and prof drd horia orasanu and must developed as followed thus questions ,then must used GALOIS Theory ,and important algebraic equations and retained of class in these rings
April 4, 2019 at 7:26 am
these relations are fundamental and can be extended and used in important equations observed prof dr mircea orasanu and prof drd horia orasanu ,or these followed to solved important algebraic equations or that appeared in associated ordinary differential equations