Given the following picture of three beams… with a given force applied at the apex… let’s see if we can work out the internal forces in the beams, and the reaction forces at the two bottom points.

This is an example of a “statically determinate” problem. We will be able to solve this assuming that the three beams do not bend or compress or stretch.
I think we can be more precise, a little later.
Our first assumption, then, is that each beam is perfectly straight… and our second is that the coordinates of the joints are set by the lengths of the beams.
Then we will assume that all forces are applied to joints. So, we have point loads at joints… no distributed loads.
Oh, let me throw in our zeroth assumption: the structure is in equilibrium. Or, if you will, we are asking what forces must be applied by the beams in order that the structure be stationary.
The whole process is simplified by one crucial fact: conservation of angular momentum tells us two things:
- that the forces at the ends of a beam are equal and opposite;
- that the forces act along the beams. (That is, the directions of the beams determine the directions of the forces.)
Let me return to being more precise. Suppose we have j joints, and m beams, and c unknown external forces. Then we will have m + c unknowns… because there’s one force for each of m beams. And at each joint, we will have two relations – x- and y-components – for a plane truss; or three relations – x-, y-, and z-components – for a space truss. That is, we will have either 2j or 3j equations.
A truss is said to be statically determinate if the number of equations matches the number of unknowns; for a plane truss, that’s
m + c = 2j.
This is a necessary condition for solving the system: if we have m + c = 2j, then we have as many equations as unknowns – but, in principle, the equations might not all be independent, and we could be unable to solve the system.
If, instead, m + c < 2j, I have read that there are two few beams m, and the structure will collapse. If, on the other hand, m + c > 2j, then the truss is said to be statically indeterminate, and we would have to decide what bending, stretching, or compressing – i.e. what deformations – the beams undergo. We would not be able to assume that all of them were still straight and at their design lengths.
The following problem comes from Pilkey & Pilkey, “Mechanics of Solids”, Quantum Publishers, Inc., 1974; example 1.10, pp. 23-25. (They, of course, did not use Mathematica®.)
One last thing before we start. The standard symbol at the bottom left says that that joint is fixed, and therefore can have a ground-reaction force with both x- and y-components. The symbol on the bottom right – with two wheels – says that the lower right joint is free to move sideways – so there can be no sideways reaction force on it!
(BTW, m = 3, j = 3, and because there is only a y-component reaction force on the right support, c = 3… so we have m + c = 2j = 6.)
The drawing lets us assign coordinates to the three joints. I chose to run the y-axis thru the apex of the structure, and the bottom two joints are on the x-axis, so my coordinates are:

Let’s draw it again, with point labels:

Now, let’s get the vectors v joining each pair of points. As much as possible, I want Mathematica to compute the vectors for this problem.

There are nine of them. Three are zero vectors, joining each point to itself. The other six are two sets of three… in which, for example, we have v_12 = -v_21, because the vector from 1 to 2 (v_12) is the opposite of the vector from 2 to 1 (v_21).
(I could remark that v is actually a function of two arguments rather than an array: single-bracket v[i,j] instead of double-bracket v[[i,j]]. The same will be true of u, f, and F.)
Next, let’s make unit vectors u out of the nonzero ones.

What I’m heading for is to write each vector as a magnitude times a unit vector. In the beam 12, for example, I will need a force vector F_12 at point 1, with magnitude f_12 and direction u_12. I will also need a force vector F_21 at 2 with direction u_21 but the same magnitude f_12. (Or, if you will, magnitude f_21 = f_12).
Let me emphasize that by construction, every unit vector points into a beam.
Let me zero-out the Fs and f:

The following line almost says that

as it should. But I made one addition: I’m sorting the indices inside f… I end up with, for example, F_12 = f_12 u_12 but F_21 = f_12 u_21. Instead of having to set f_21 = f_12, I use f_12 instead of f_21 right from the beginning. In other words, the result has no f_21 or f_31 or f_32 in it.

The (1,2) entry…

is F_12. It has unknown magnitude f[1,2], but direction – unit vector – u_12 = {4/5, 3/5).
I think I got the following by just playing around. It works out right.

The left column is the x-component forces for each of the three joints; the right column is the y-component forces for each of the three joints.
Right? The (1,1) entry…

comprises
(1) the x-component of F_12
(2) the x-component of F_13, namely f_13 – because F_13 has ony an x-component.
Let’s look at that in gory detail. The unit vector from point 1 to point 2 is

is its y-component.
Similarly, the other force at point 1 is

which has only an x-component.
Now it’s time to add in the external forces applied to our structure. At point 2, we have (100,-200)… at point 1 we could have both horizontal and vertical components (call them R1 and R2)… at point 3 – which is free to roll under a sideways force, but it isn’t rolling so there can’t be a sideways force! – we can only have a vertical reaction force (call it R3) from the ground:

We add the external forces to the internal ones:

And now, each of those x- or y-components must be zero.
(Actually, I just made a command decision. By saying that the sums of the forces are zero, I have just declared that the F forces are internal beam forces… equivalently, they are forces exerted by the beams on the joints – rather than the forces exerted by the joints on the beams. Stay with me here. I think it will be clearer after we look at the solutions.)

We have 6 equations, and 6 unknowns (R1, R2, R3, and f[1,2], f[1,3], f[2,3]). Can we solve the system?
Yes:

(Those are the answers in the book.)
To be specific, their answers are:
R2… 24; R1… -100; R3… 176. Good.
f[1,2]…-40; f[2,3]… -220; f[1,3]… 132. Excellent.
Let’s check these, at least a little. A global balance says that the reaction forces R1, R2, R3 from the ground must balance the external applied forces… so add up the vectors, add the reaction forces to the applied forces:

Good.
Now, let’s draw a picture for one beam, 1-2. (You might note that I am combining a new graphic with the original drawing, rather than re-creating the original. Takes less space… and gives me more freedom with larger trusses.)

Those outward pointing arrows emphasize that f12 is negative:

Fine… but is the beam in tension or compression?
These are the forces exerted by the beam on the joints… so the joints are pushing inward on the beam. Therefore, the beam is in compression.
Note that it takes two decisions to make this happen. First, by definition my unit vectors point inward… Second, I declared that the sum of the forces F and the external forces was zero. That the sum was zero says I am computing internal beam forces… then the inward-pointing unit vectors says that a positive magnitude is tension, a negative magnitude – as we have here – is compression.
Finally, if we think about it, we have an upward-pointing reaction force at 1, and a downward external force at 2… physically, the beam should be in compression, as we said mathematically.
If you want the arrows to point the other way on the picture, you have two choices. One, you could just draw -F instead of F. Two, instead of writing the force balance as 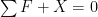
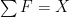
You might have noted that what I drew was scaled, F/10 instead of F. Without scaling, we get

What about beam 2-3?

It’s in compression, too: the beam is pushing back against the joints at 2 and 3.
I could draw beam 1-3 alone… but let me show you all three at once:

In contrast to the other two beams, 1-3 is in tension; i.e. f[1,3] is positive.

Let me show you the other way to reverse the arrows. I return to a point just before I set up the equations we solved. Instead of

We still have 6 equations, and the same 6 unknowns (R1, R2, R3, and f[1,2], f[1,3], f[2,3]).

Recall the book answers: R2… 24; R1… -100; R3… 176. Excellent.
f[1,2]…-40; f[2,3]… -220; f[1,3]… 132. Reversed! Also excellent.
I happen to have changed the scaling on these forces. Don’t let that distract you from the important change, namely the reversed arrows.

which agrees with the altered signs: 1-2 and 2-3 are positive, hence in compression, 1-3 is negative, hence in tension.

Right? By setting the sum of the forces 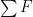
I suppose I should be explicit. We have left one of our two choices intact: f > 0 means that the corresponding F points into the beam; but now each F is the force applied by a joint to the beam. The effect of these two choices is that f > 0 is compression instead of tension.
Next time, I think, a slightly more complicated example.
BTW, the first time I worked this example, it was nowhere near as organized (with arrays for vectors v, unit vectors u, magnitudes f, and forces F. The organization was the result of working more complicated problems.

November 8, 2017 at 11:00 am
For small temperature intervals hfg can be treated as a constant at some average value. Then integrating this equation between two saturation states yields
November 8, 2017 at 11:03 am
LEAST MULTIPLIERS
The Least Common Multiple of two integers, is the least positive integer that is divisible by both integers. This is connected by a simple formula with the greatest common divisor of the two integers, a familiar topic from modern algebra and number theory. The purpose of this paper is to present a proof for the connection between least common multiple and greatest common divisor. Along the way we will see several other properties of the least common multiple, as well as a number of examples.
Throughout the discussion, we will consider only positive integers, the set of which is expressed as N. We also assume the notation and properties of the greatest common divisor presented in Hungerford [1]. In particular, if a and b are positive integers, we denote the greatest common divisor of a and b by (a,b). To begin the discussion of least common multiple, we present the following definition.
Definition 1. If a and b are positive integers, the least common multiple of a and b, denoted [a,b], is the least positive element of the set {z N : a | z and b | z }.
It should be remarked that for any positive integers a and b, their product a
We see that 12 is the least entry that is common to both sets. Indeed, 4|12 and 6|12 so 12 is definitely a common multiple. On the other hand, since the only positive multiple of 6 less than 12 is 6 itself, and since 4 is not a divisor of 6, we see that no other common multiple can be less than 12. This shows that 12 is the least common multiple.änd prof dr mircea orasanu and prof horia orasanu
In this example, we notice that 12 is not only less than or equal to every other common multiple of 4 and 6, it is also a divisor of all those multiples. We state this as a theorem.
b is always divisible
November 8, 2017 at 11:20 am
here we give some aspects as GREEN FORMULA and LAGRANGIAN associated
The solution of partial differential equations describing a wide range of physical problems in a domain can be reduced to the solution of corresponding boundary integral equations (BIE) on a boundary . The solution of boundary integral equations leads to the retrieval of unknown boundary values of the functions and/or the derivatives of these functions that occur in the original differential equation. There exists a class of problems, where the finding of boundary values of unknown functions on a given domain is, from the application point of view, quite sufficient. As an example, we can mention the calculation of the stress intensity factor for a cracked body, which can be determined in terms of calculated displacements of crack faces. In this case, the calculation of stress-strain field in internal points of a domain is unnecessary. However, if we are also interested in values of functions inside the domain, we can calculate them from the known boundary data using appropriate integral relations. These integral relations are e.g. Green’s formulas for the case of Laplace’s or Poisson’s equation. We will see that, in case of elasticity problems, the appropriate integral relations are so-called Somigliana’s formulas, which are equivalent to Green’s formulas.
The BIE can rarely be solved analytically. One of the most used techniques to their solution is the boundary element method (BEM). In order to solve for the unknown surface data, the surface must be subdivided into segments (i.e. elements similarly as with the standard FEM) and, as a results, the boundary integral equations are approximated by a system of algebraic equations. The boundary elements have one less dimension than the body being analyzed. That is, the boundary of a two-dimensional problem is surrounded by a one-dimensional elements, while the surface of a three-dimensional solid is paved with two-dimensional elements. Consequently, boundary element analysis can be very efficient, particularly when the boundary quantities are of primary interest. BEM solutions have been found to be quite accurate, especially when the domain is infinite or semi-infinite, such as often occurs with stress concentration or crack problems.
The method is particularly appropriate for linear problems. Extensions into the nonlinear range are possible, but at the expense of some of the special advantages of the method. As the advantages of BEM in comparison to FEM, there are usually considered a lower number of unknowns, a higher accuracy of approximation of derivatives of unknown functions and an easy analysis of infinite domains.
There are two basic approaches leading to the formulation of BIE. The first approach, i.e. so-called direct formulation, leads to the construction of integral equations, which contain as unknown functions those functions, which stand in original differential equations. The second approach, so-called indirect formulation, leads to the integral equations which contain as unknown functions so-called single layer potential densities and double layer potential densities, from which the searched functions, standing in the differential equations, must only be computed.. While the theoretical basis of the direct formulation is the so-called fundamental solution of a differential equation, or Green’s function respectively, which is used together with Green’s formulas, or Somigliana formulas respectively, the basis of the indirect formulation is so-called theory of potential. Some basic principles of the theory of potential, necessary for the indirect formulation of BIE corresponding to Laplace’s equation and/or Poisson’s equation, are given in Appendix 2. (back to Lecture 8)
The direct formulation will first be demonstrated at one-dimensional problem, where the concept of Green’s function is better to elucidate. Also it will become clear how a searched function is expressed using its boundary values and the boundary value of its derivations. given by prof dr mircea orasanu and prof horia orasanu that are used for Green formula and LAGRANGIAN Formula Green’s function G(x,) of the operator A is defined as a solution of Eq. (1), where the function f is the Dirac delta function, f(x)= (x–), and satisfying given boundary conditions. It means that G(x,) fulfils the equation
(3)
for the same boundary conditions that the function u(x) is required to satisfy. Therefrom it follows the relation
. (4)
The conception of Green’s function has a substantial theoretical meaning, since it makes possible to solve a differential equation with suitable boundary conditions be means of the quadrature. It can be seen from the following: By using the Dirac delta function, the equation (2) can be written as
, (5)
wherefrom, using the definition of Green’s function (4), we get
. (6)
Green’s function is often called the influence function, which is motivated by its physical meaning. Consider, e.g. a beam supported at its end points a, b, and subjected to unit concentrated load at the point x = . Then, Green’s function G(x,) of this problem describes a beam deflection w(x), which is caused by the unit concentrated load. If instead of the concentrated load, the beam is subjected to a load f() at the point x = , the deflection will be given by G(x,)f(). If the beam is subjected to a distributed load f(x), then its deflection is
. (7)
This is the physical meaning of Eq (6), (in general case, the meaning is similar).
However, in the boundary integral equation method, we are not concerned to set up Green’s function for a particular boundary value problem – this is frequently unsolvable problem. We make do The basic features of the boundary element method will now be explained with a beam deflection example. We begin with the integral (global ) form of the equation of equilibrium and boundary conditions. Mathematically, we require the equation of equilibrium and boundary conditions to be fulfilled in the weak sense, see Lecture 4. In the case of 3D problem, the integral form of the equations of equilibrium and the boundary conditions can be written in the form (back to Lecture 8)
. (8)
Eq. (8) is sometimes referred to as the extended Galerkin’s method, where the basis functions need not satisfy boundary conditions. In other words, we require the differential equations of equilibrium and boundary conditions to be fulfilled in the mean with a certain weight. As the weight functions, we have selected the variations of sought functions. These procedure can be considered as a special case of the weighed residual method described in Lecture 5-6. The special one in the sense that the weight functions may be chosen quite arbitrarily, and specific selections lead then to the FEM, the finite difference method, the collocation method, and BEM.
For a beam, the equation (8) takes the form:
By virtue of integration by parts, the fundamental solution enables us to express the solution in an interior point of a domain in terms of its boundary values, and if we let move the interior point to the boundary, we obtain the integral equation, from which the unknown boundary value can be computed. Obviously, in the case of one-dimensional domain, the boundary degenerates into one (two points), and instead of boundary integral equations, we have simple algebraic conditions expressing the equality of function values. (back to Lecture 8)
, (9)
where T and M stand for the shear force and the bending moment respectively, , w and denote the deflection and the slope respectively, and denote the prescribed values at the ends of a beam.
Application of integration by parts to the first term of Eq. (9) gives
. (10)
Continuation of this process applied to the integral on the right-hand side of (10) leads to
and eventually to
. (11)
Substitution
November 9, 2017 at 8:08 pm
Most optimization problems have constraints of different types which modify the shape of the search space. During the last two decades, a wide variety of Problems) has dimensions between 2 and 20 which is very low. In addition, CEC 2006 benchmark has been solved satisfactorily by several methods. Therefore, it has become impossible to demonstrate the superior performance of newly designed algorithms. Therefore, there is an urgent need to upgrade the current test suite by increasing dimensional scalability and by considering the types of constraints (equality, inequality, linear, nonlinear, dimensionality, active, etc.), types of objective functions (linear, quadratic, nonlinear, multimodality, separability, etc.), connectivity / relative size of feasible region and so on. In addition, it would be beneficial to evaluate and, if necessary, develop novel performance measures to deal with the diverse characteristics of the real-world constrained optimization problems. We plan to present an extended test suite and standardized evaluation measures for researchers to test their algorithms till the CEC’2010 submission deadline in late January 2010. Along with the papers, we would also optionally like participants to submit their codes and we shall put it up on a web-site for anyone to try out. The submitted papers will be peer-reviewed and selected authors will be invited to present their results during CEC-2010. We hope this exercise will be helpful for researchers interested in this field and may generate new ideas to advance the research in this area. metaheuristics have been designed and applied to solve constrained optimization problems. Evolutionary algorithms and most other metaheuristics naturally operate as unconstrained search techniques. Therefore, they require an additional mechanism to handle constraints during the search process. Historically, the most common approach to handling constraints are the penalty functions originally proposed in the 1940s and later expanded by many researchers. Penalty functions are not effective if the optimum lies in the boundary between the feasible and the infeasible regions or when the feasible region is disjoint. Researchers have also proposed a number of other approaches to handle constraints such as the self-adaptive penalty, epsilon constraint handling and stochastic ranking. Developing novel constraint handling methods and investigating the performances of search engines on solving constrained problems have attracted much interest recently.
Irrespective of the high level of interest in constrained real-parameter optimization, the current constrained optimization test suite (CEC 2006 Benchmark
November 9, 2017 at 8:12 pm
Start by considering an arbitrary surface S (it can be as irregular as you like—it doesn’t even have to be a polyhedron). Divide up the interior into N little cubes. As you might expect, we’re going to approach this problem in the same way that we used Riemann sums in order to get us to the area under a curve. Here, we’re going to find the flux through a bunch of cubes and then let the size of each cube go to zero (equivalently, we let the number of cubes go to infinity). The approximate flux that we get for the surface by adding up the fluxes through all the cubes will become the exact flux through the surface S as we let the number of cubes approach infinity Obviously, we can obtained the following relationships from Eqs
and
December 30, 2018 at 6:54 am
,
December 30, 2018 at 7:03 am
and thus prof drd horia orasanu
January 8, 2019 at 4:12 am
,
January 19, 2019 at 10:37 pm
in many situations can be approached special aspects as observed prof dr mircea orasanu and followed with studies of prof dr GIGEL MILITARU in case of Adrien LEGENDRE
February 23, 2019 at 10:20 pm
in found are obtained as