As I draft this, I plan to do four things in this post.
- Summarize the methods I’ve used to analyze multicollinearity.
- Suggest that multicollinearity is a continuum with no clear-cut boundaries.
- Summarize the conventional wisdom on its diagnosis and treatment.
- Flag significant points made in my posts.
Let me say up front that there is one more thing I know of that I want to learn about multicollinearity – but it won’t happen this time around. I would like to know what economists did to get around the multicollinearity involved in estimating production functions, such as the Cobb-Douglas.
Methods
I have used three tools for assessing multicollinearity. The one that surprised me was the Variance Inflation Factors (VIF). In general they are now the first tool I use; in many situations, they may be the only tool we need to use. Nothing I know of is more definitive for multicollinearity.
I had expected that the singular values (from the singular value decomposition) would be the definitive tool – they are as definitive as anything can be for exact linear dependence – but they are secondary to the VIF for multicollinearity in my toolbox.
Finally, if we’re close to exact linear dependence, the third tool is to investigate the nature of 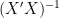
Thus:
- VIF or R^2 VIF
- Singular Value Decomposition (SVD)
- the inverse of X’X
Let’s recall a little more about these tools.
The definition of the Variance Inflation Factors is

and I choose to invert that definition. Given the VIF by Mathematica®, I compute

and call them the VIF R^2.
One major advantage of using the VIF R^2 (or the VIF themselves) is that they do not depend on scaling of the data. For example, they were the same for the raw Hald data, the centered Hald data, and the standardized Hald data. This is the only one of the three tools that is not affected by scaling. So, even though we are unable to draw a line and say, “On this side, multicollinearity; on that side, not,” the VIF R^2 provide a consistent quantitative measure of multicollinearity.
(Okay, there is one problem with that. We get more than one measure. For the four variables of the Hald data, we get 4 VIF R^2, one for each variable as a function of the other three. Still, we get the same four VIF R^2 for the raw data, the centered data, and the standardized data. And that we got four significant values told us that all four variables were involved in the most serious multicollinearity. We don’t want just one VIF or VIF R^2.)
A major advantage of using the VIF R^2 as opposed to the VIF themselves is that we may have better intuition for the values of R^2 than for the values of the VIF. I do, anyway.
Finally, I find the VIF R^2 to be rock-bottom satisfying… I want to know if some variables are linearly related – and that is precisely the question asked and answered by the VIF R^2.
The most specialized of our tools is the third one: checking the inversion of the matrix X’X. Most of the time, there’s utterly no reason to even think of checking the inverse for numerical accuracy… but sometimes the solution process spits out warning messages, or sometimes the solution itself looks suspicious, or we might check it because the VIF R^2 are 1 or awfully close to it.
At that point, I ask explicitly for the inverse… now I might see some warning messages… and then I can check the inverse to see how well it works.
So I’m taking the behavior of the inverse of X’X to be my touchstone for linear dependence. All I’ve done, however, is let someone else set the cutoff: the authors of the code decided when warning or error messages are to be printed.
Checking the inverse of X’X, then, is one tool for diagnosing multicollinearity; in fact, it flags extreme multicollinearity, almost linear dependence, and exact linear dependence.
I’ll have more to say about checking the inverse when I talk about multicollinearity as a continuum.
The third tool we have for assessing multicollinearity is the singular value decomposition of the design matrix X (that is, the “data” plus a column of 1s if there’s a constant term in the fitted model):
X = u w v’.
There are four ways that I know of for using the SVD for multicollinearity:
- Look at the singular values (the diagonal entries of w)
- Look at the condition number (the ratio of largest singular value to smallest)
- Compute X.v and see what rounding will make columns disappear.
-
Set the smallest singular value to zero in the w matrix (rename it
), and see how close the recomputed
is to X.
The SVD suffers from the same defect as inverting X’X: it is sensitive to scaling of the data. We saw this for the three forms of the Hald data.
Nevertheless, once the VIF R^2 have fixed the severity numerically, then I can use the SVD to assess relative severity. We were able use the relative severity of m/c in the three forms of the Hald data, and reach many of the same conclusions.
But not all. Sometimes the singular values flag relationships that really are not multicollinear. I tell myself that the SVD is flagging weak threats to the inversion of X’X.
I had hoped that the SVD would be definitive for multicollinearity, but its sensitivity to scaling precludes that. Why did I think it would be definitive? Because it is definitive for exact linear dependence: the determinant of X’X is 0 precisely when one or more eigenvalues of X’X are 0… precisely when one or more singular values of X are 0… precisely when one or more columns of X.v are exactly 0.
Unfortunately, we have multicollinearity when those things are close to zero – for vague meanings of “close”.
In summary – get the VIF R^2 almost as a matter of course; they’re cheap. Look at the inversion of X’X if we suspect that the data are almost linearly dependent. Look at the singular values if I want to identify all the multicollinearities. (The Hald data had three different multicollinearities.)
A Continuum: Orthogonality, Multicollinearity, and Linear Dependence
Let me talk about a continuum of multicollinearity. Let me start by reviewing (exact) linear dependence.
A set of vectors is linearly dependent if there is some linear combination of them which adds up to the 0 vector. A set of vectors is linearly independent if it is not linearly dependent. Consequently, any set of vectors is either linearly dependent or linearly independent. We could draw the following diagram:

Everything is fine. Linearly independent and linearly dependent are mutually exclusive and exhaustive. (This hinges on the fact that 0 is exactly 0.)
Furthermore, we have a few simple tests in principle. We could use the SVD: arrange the vectors as columns of a matrix X… get the singular value decomposition X = u w v’… and compute X.v . If the vectors are linearly dependent, then the matrix X has a nontrivial null space… and the rightmost columns of v are a basis for it… and, by definition, X applied to those rightmost columns gives columns of zeros. That is, one or more of the rightmost columns of X.v will be all zeroes whenever we have linear dependence.
Or we could compute the determinant of X’X. Or, essentially equivalent to the SVD, we could compute the eigenvalues of X’X. Or we could compute the singular values of X. In each case, a value of zero indicates linear dependence.
We saw this exactly in the 2nd post about linear dependence.
In the post titled “you inverted what matrix?”, we had a matrix whose columns were linearly dependent… but the values of the rightmost column of X.v were 10^-14 instead of 0. And in this post we saw that the smallest singular value was about 10^-12. (I had to force Mathematica to display it; its default shows 0 – which is what I really want for the answer….)
In principle those columns – in both examples – were linearly dependent… But do we know where to draw the line numerically? I don’t see how. I would have to say, in fact, that in practice there is no clear-cut dividing line between linearly dependent and multi-collinear. It depends on the computer hardware and on the linear algebra software. And on the specific set of vectors.
Don’t misunderstand. Sometimes we can decide between “multicollinear” and “linearly dependent” – e.g., for matrices of integers where we can see the exact linear dependence from the beginning. The issue, however, is that I cannot know that because the elements of the rightmost column of X.v are all less than 10^-6, then we have linear dependence. I may choose to call it such – but I think I’m making an arbitrary decision about how close is close enough.
I want to believe that Mathematica might say it cannot do it: X’X cannot be inverted. We’ve seen, however, that it delivered a model when X’X in principle could not be inverted. Although it is very rare for Mathematica to fail to get a regression model – in fact, I wish it would fail more often – your software may not be so reckless.
One solid feature of multicollinearity is that it is a continuum. We’ll get to a picture of it… but first I want to consider the other extreme of the continuum.
Orthogonality.

The diagram simply says that every set of orthogonal vectors is linearly independent, but not conversely. (Any two non-collinear vectors in the plane are linearly independent, but “most” such pairs are not orthogonal.)
We have seen in a few examples that we can completely eliminate multicollinearity by making our data mutually orthogonal. What’s going on? Given two vectors, we could consider the projection of one onto the other. Equivalently, we could break one of them into components parallel and perpendicular to the other.
If one has no component parallel to the other, then the two vectors are perpendicular, i.e. orthogonal. But if one does have a component parallel to the other, doesn’t that constitute partial – i.e. approximate – linear dependence – i.e. multicollinearity?
Both not-quite-linear-dependence and not-quite-orthogonal can be considered multicollinearity. At one end, very severe, and at the other, very mild.
Let’s look at a 2D case. Here are five vectors in the xy-plane.

Any two of these vectors are linearly independent; any three or more are linearly dependent. Vectors a and b are orthogonal. the two pairs b and d, and a and c, are nearly parallel, hence strongly multicollinear. On the other hand, the pair c and d (or c and b, or a and d) are nearly orthogonal.
And what about e? It’s at a 30° angle from the x-axis (and of length 1). Its projections onto a and b (which are unit vectors) are the cosine and sine of 30°, i.e.

Those are not all that small compared to the length of e. How multicollinear is the set {b, e} ? The set {a,e}? I don’t know how much – but I would say they are multicollinear.
(I say again, the set {a, b, e} is exactly linearly dependent: 3 vectors in a 2D space.)
Anyway, if you accept this as a plausibility argument that orthogonality is the other end of the continuum from linear dependence, I can offer the following picture:

As we have seen, we can assign numbers to that continuum: if the vectors are orthogonal, then the R^2 computed from the VIF is 0; if the vectors are linearly dependent, the VIF R^2 is 1. So let me assign numbers:

Let’s look at that. The red circle on the right is intended to say that there’s a small region, not just a point, where we’ll conclude that the data is linearly dependent. But it’s a vaguely defined region (R^2 = .9999 or .999999 or 1-10^-10 or 1-10^-14….?). Everything else is linearly independent – and except for the left-hand blue disk, multicollinear to some extent.
Conventional Wisdom
Now let’s talk about the conventional wisdom.
How do we detect multicollinearity? Why do we care? What do we do about it?
Because my early training in regression was at the hands of economists, and in an era when regression was expensive, I originally learned the conventional approaches to detecting multcollinearity… and that’s reflected in my commentary. Because I have come to use stepwise methods to run regressions, however, I use particular forms of detecting it.
To be specific, I pay attention to t-statistics which fall (in absolute value) as more variables are introduced. More generally one could look for a high R^2 for the fit, with low t-statistics… or one could look for high values in the correlation coefficients.
Once one suspected that the data might be multicollinear, one could check – as I have – to see if the fit is sensitive to the data. Do the odd-numbered and the even-numbered rows of the data matrix lead to different fits? Does dropping a column (variable) from the data lead to a different fit?
Today, I view that as one way of assessing the severity of the multicollinearity – how sensitive is the fit to the data set?
One might also have been told to look for variables whose coefficients have the “wrong” sign. Again, it’s a possible side-effect of multicollinearity but – as I argued in the Toyota post – it’s actually a very reasonable consequence: the difference between a partial derivative and a total derivative.
Personally, I would now automatically look at the VIF R^2 for any regressions of interest. As I said earlier, they’re trivial to compute. It’s not as though some student has to be told to go run two dozen regressions overnight in order to get the results to you tomorrow. (Been there. Done that.)
If I couldn’t actually compute the regression, or if I got warning messages, or if the VIF R^2 were almost 1, then I would investiage the inverse of X’X.
Finally, I might use the SVD to identify the muticollinearity or multicollinearities.
Let me say most of that another way; here’s what I do. Because I favor the running of stepwise sets of regressions, I can’t avoid seeing if t-statistics fall as some variables are added, and so I may suspect multicollinearity as soon as I’ve run my fits. But the VIF R^2 will then tell me what multicollinearity I have, so they are my usual first check – unless the inversion of X’X looked flaky. Looking at the SVD is now reserved for an in-depth analysis. (No regression of interest contained both X1 and X3, so the VIF R^2 of the regressions I focused on would not have shown the relationship between X1 and X3. That’s what the SVD gave me.)
My point is that I do not worry about coefficients with “wrong” signs, nor would I usually check for sensitivity of coeffcients on the data – at least, not for detecting multicollinearity. I might care about the signs, and I might care about sensitivity – but for me those are separate issues, not “tells” for multicollinearity.
Why do we care?
I would like to quote Johnston (“Econometric Methods”, 2nd Ed, McGraw-Hill 1972, p. 160). Even the 4th edition is out of print, so I think a long quotation is justified (ellipses are mine). It’s a beautifully compact summary.
“The main consequences of multicollinearity are the following:
“1. The precision of estimation falls so that it becomes very difficult… to disentangle the relative influences of the various… variables. This loss of precision has 3 aspects: specific estimates may have very large errors; these errors may be highly correlated…; and the sampling variances of the coefficients will be very large.
“2. Investigators are sometimes led to drop variables incorrectly from an analysis… but the true situation may be not that a variable has no effect but simply that the set of sample data has not enabled us to pick it up.
“3. Estimates of coefficients become very sensitive to particular sets of sample data, and the addition of a few more observations can sometimes produce dramatic shifts in some of the coefficients.”
Let me talk about some of that. In a nutshell, the t-statistics may be low, the values of the coefficients may be hghly uncertain, the values of the coefficients may be related to each other, and may be sensitive to the addition or deletion of data. He also said that a low t-statistic might lead us to drop a variable incorrectly.
Does uncertainty in the coefficients matter? Sometimes, sometimes not.
If we are trying to estimate coefficients in a theoretical equation – if we’re going to tell the Chairman of the Federal Reserve Board that raising this interest rate by 0.25 will cause purchases of those bonds to rise 5% – then it really matters how trustworthy a single coefficient is.
But if we have significant multicollinearity, then the variances of some coefficients may be very large (that’s hand in glove with t-statistics being small), and we do not have have tight estimates for those coefficients.
It’s unfortunate that we can eliminate the multicollinearity completely – but end up with difficult-to-interpret variables. I’d like to see a thorough example of what economists actually do to work around multicollinearity themselves… but I haven’t found one. For what it’s worth, production functions (e.g. Cobb-Douglas) may be a fruitful topic for this.
On the other hand, if we’re just trying to get an equation for interpolation, we may not care whether the individual coefficients are tight, so long as the fit itself is tight. Or, if we’re never going to change the data set, we may not care that the fit would change if we dropped half the values, or added more.
As for dropping a variable we should keep, because of a low t-statistic – that’s one reason for favoring stepwise, forward, and backward selection methods. We get more information about each variable. In addition, we have the SVD, whose singular values may provide more information about specific variables.
Those are the risks. On the other hand, Ramanathan (“Introductory Econometrics with Applications”, 3rd ed, Dryden, 19995, p. 315) points out that “… the OLS estimators are still BLUE [best linear unbiased estimators]…. the distribution of the t-statistic is also not affected…. OLS estimators are still maximum likelihood and are hence consistent. Forecasts are still unbiased and confidence intervals are valid…. Although the standard errors and t-statistics… are numerically affected, tests based on them are still valid.”
That is, there are many reasons not to care about some level of multicollinearity.
If we do care, what do we do about it?
Ryan (“Modern Regression Methods”, 1997, Wiley Interscience, p. 138) objects to dropping variables: “In general, selecting regressors to delete for the purpose of removing or reducing multicollinearity is not as straightforward as it might seem here…. Consequently, deleting regressors is not a safe strategy with multi-collinear data.” He goes on to suggest ridge regression as an alternative.
Ramanathan (op. cit., p. 319-321) lists more alternatives, warning, however, that “A great deal of judgment is required in handling the problem.”
- Benign neglect
- eliminating variables
- reformulating the model
- using extraneous information
- increasing the sample size
- ridge regression or PCA (principal component analysis)
to which I would add:
- orthogonalize the data.
(I can’t believe I’m the first person to orthogoalize everything, including the constant and any dummy variables. But why do people keep saying that we cannot eliminate multicollinearity?) That introduces another issue – how do I interpret the resulting variables? – but we face that problem with PCA, too; but by orthogonalizing the data, we can completely eliminate multicollinearity. We have seen that linear dependence – as opposed to multicollinearity – is reflected in an inability to construct as many orthogonal variables as the number of variables we started with.
As I see it, the problem with PCA is that the variables are as difficult to interpret as when we orthogonalize, but without the benefit of eliminating the multicollinearity.
Reviewing the Posts
I want to hit some of the high points of the multicollinearity examples. Actualy, I guess I mainly want to focus on specific things we learned from each post, not to summarize them again. Let me try to more or less run through them latest to earliest – i.e. in the order you will find them.
Let me start by emphasizing that we can eliminate multicollinearity by orthogonalizing all the independent variables – including the constant term and any dummy variables. We did this to the Hald data, the Toyota data, and the ADM (Archer Daniel Midlands) data.
In the previous post, we saw that we could use the QR Decomposition to orthogonalize data (as Q), and that the R matrix would give us the relationship between the original and the orthogonal data. The key is that we are still left with a constant column.
In the second ADM post, we saw that just centering the YEARS (so that we had -7/2 to +7/2 in integer steps) eliminated error messages and caused forward and backward selection to agree on the fits.
In the first ADM post, we had terrible coefficients in the fits, warning messages, and unreliable inverses of X’X. Nevertheless, perhaps shockingly, the fits were pretty good. In addition, we saw how orthogonalizing could fail: we were unable to create 7 orthogonal variables. I infer that we were effectively – computationally – dealing with a few dimensions of linear dependence.
In Example 8, our first polynomial regression, we saw that forward and backward selection did not agree; most importantly, backward selection dropped the true variable first. It’s worth knowing that backward selection can’t always cope with a lot of poor t-statistics. (That’s why I avoided it for years, until practice showed me that it could be reliable despite the presence of some level of multicollinearity.)
When we eliminated multicollinearity from the Toyota data, we saw that we had to orthogonalize the dummy variables, too.
When we eliminated multicollinearity from the Hald data, we orthogonalized the constant term as well as the “data”. We saw that eliminating multicollinearity did not change the lack of a clear-cut choice between using two independent variables or three. That may be all the useful information that resulted from orthogonalizing the data: the goodness-of-fit was not negatively impacted by the multicollinearity.
In the post about “you inverted what matrix?”, we saw our second example of exact linear dependence in principle but extreme multicollinearity in practice: we got a fit, but the computed inverse of X’X was garbage. (The first example was the Bauer matrix back in the first linear dependence post.)
In example 6 we investigated sensitivity to splitting the data into subsets. We saw an inverse of X’X that worked pretty well despite a warning message.
In Example 5, the Toyota data, we saw why the strange sign on MILES is actually plausible. We saw a significant improvement to the fit by using dummy variables. We also saw that the required rounding to eliminate the last colun of X.v was rather extreme – to the nearest “2”. Interestingly, the VIF R^2 suggested that the multicollinearity was more severe than in the Hald data – but the SVD suggested it was less severe.
In several posts about multicollinearity in the Hald data, we looked at the raw data, the centered data, and the standardized data. (There was a later, final post in which we eliminated the multicollinearity.) We used the SVD in various ways, and the VIF R^2. We used the Hald data to see how Mathematica® computes an eigenstructure table. We saw that sometimes the SVD quibbles over threats to inversion from rather safe matrices: sometimes it suggests multicollinearity where the VIF R^2 show none.
In the first post about multicollinearity in the Hald data, we saw the inadequacy of the correlation matrix. Most importantly, perhaps, we saw that we could have more than one multicollinearity in a data set.
We began our investigation with a couple of posts about exact linear dependence. In this post, we saw the linearly dependent Bauer matrix, and a misguided attempt at treating it as though it were merely multicollinear. In the second post, we saw that X.v could nail exact linear dependence.
Enough.

Leave a comment